VRGaussianAvatar:用一张照片生成3D虚拟人,实现实时VR驱动

需一张普通照片,就能快速生成全身3D虚拟人,并且仅靠VR头显自身的传感器就能实时驱动
(映维网Nweon 2026年03月18日)在虚拟现实中,一个看起来像自己、动作也同步的虚拟化身,能极大提升沉浸感和社交体验。过去要生成这样的“数字替身”,往往需要复杂的设备、长时间的视频录制,或者最终效果不够逼真。如今,韩国科学技术院和苏黎世联邦理工学院等机构组成的研究团队带来了一套名为VRGaussianAvatar的新方案,只需一张普通照片,就能快速生成全身3D虚拟人,并且仅靠VR头显自身的传感器就能实时驱动。
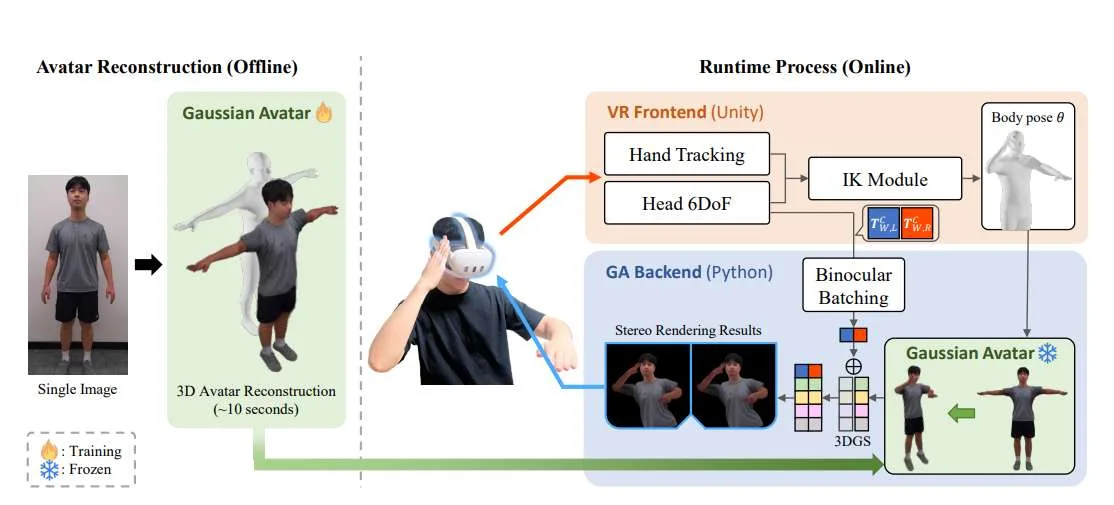
传统方法中,想要在VR里拥有一个高精度的虚拟人,要么需要专业的多相机阵列,要么依赖耗时的视频处理。VRGaussianAvatar则大幅简化了流程:用户只需提供一张正面全身照,系统在10秒内就能完成3D高斯飞溅模型的构建。这个模型不仅还原了用户的面容、衣着细节,还能通过标准的骨骼绑定进行动画驱动。
更关键的是,在运行时,系统仅依靠商用VR头显内置的头手追踪信号,通过逆向运动学算法推算出全身姿态,完全不需要额外的手柄或外部追踪器。这意味着用户戴上头显后,就能立刻“进入”自己的虚拟身体,动作实时同步。
......(全文 914 字,剩余 492 字)











