告别昂贵设备与人工标注:Meta以数据驱动方式重塑VR面部追踪

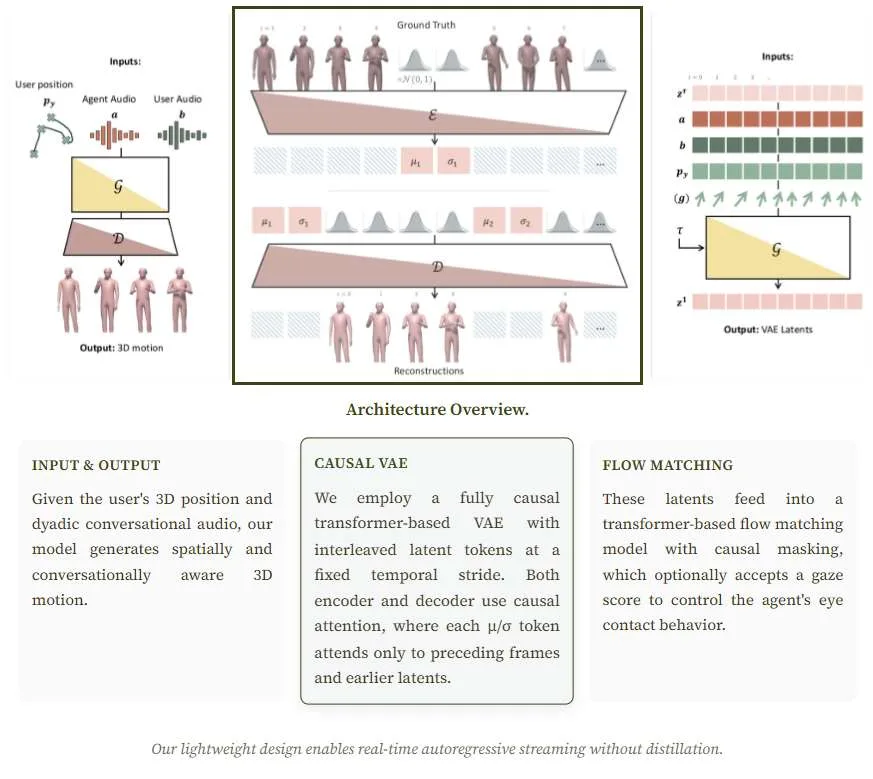
基于红外摄像头的实时面部表情追踪系统
(映维网Nweon 2026年02月26日)Meta Reality Labs团队介绍了一种名为REFA的实时面部表情方案,它能够利用嵌入VR头显中的红外摄像头所捕获的第一人称视角图像,实时追踪面部表情,以便用户能够以非侵入式方式精准驱动虚拟化身的面部表情,且无需冗长的校准步骤。
作为数据集构建工作的一环,研究人员采用轻量化采集方案,仅需搭配定制摄像头的VR头显与智能手机,采集了涵盖1.8万名多样化受试者的面部数据。为处理数据,他们开发了鲁棒的可微分渲染管道,可自动提取面部表情标签。

传统的VR面部追踪面临三大挑战:头显遮挡面部导致难以捕获完整表情、额外增加摄像头带来的成本和复杂性、以及移动平台的计算限制。这使得虚拟化身常常呈现出僵硬的表情。
......(全文 1068 字,剩余 768 字)