EgoWorld框架实现从第三人称视角到第一人称视角的转换

将第三人称视角转换为第一人称视角
(映维网Nweon 2025年11月06日)自中心视觉(Egocentric vision)对于视觉理解至关重要,特别是在捕获操作任务所需的详细手部-物体交互方面。将第三人称视角转换为第一人称视角,能极大地惠及增强现实和虚拟现实等应用。然而,当前的外中心(exocentric)到自中心(egocentric)视角转换方法受限于其对2D线索、同步多视角设置以及不现实假设(例如在推理过程中需要初始自中心帧和相对camera姿态)的依赖。
为了克服所述挑战,LG,韩国科学技术院,英国牛津大学团队入了EgoWorld。这个新颖的两阶段框架能够从丰富的外中心观察(包括投影点云、3D手部姿态和文本描述)中重建自中心视角。所提出方法从估计的外中心深度图重建点云,将其重投影到自中心视角,然后应用基于扩散模型的修复技术来生成密集、语义连贯的自中心图像。在H2O和TACO数据集上的评估表明,EgoWorld实现了最先进的性能,并展示了对新物体、动作、场景和主体的强大泛化能力。另外,即使在未标记的真实世界示例上,EgoWorld都显示出有希望的结果。
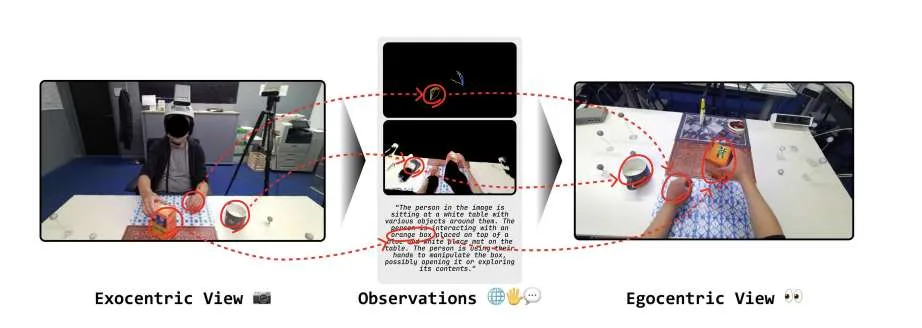
自中心视觉在推进人类和智能系统的视觉理解方面扮演着关键角色。自中心视角对于捕获详细的手部-物体交互特别有价值,并在烹饪、组装或演奏乐器等技能密集型任务中至关重要。然而,大多数现有资源是从第三人称视角录制,这主要是由于头戴式摄像头和可穿戴录制设备的可用性有限。因此,从外中心输入生成或预测自中心图像的能力,对于增强现实和虚拟现实等应用具有重大潜力。
......(全文 3765 字,剩余 3224 字)








