新墨西哥大学提出实时端到端Transformer姿态估计方法DETRPose

基于Transformer的实时端到端姿态估计方法
(映维网Nweon 2025年10月30日)多人姿态估计(MPPE)任务旨在检测图像中所有人体关键点。作为计算机视觉与虚拟现实领域多项应用的基础任务,目前尚未出现能够实时运行的基于Transformer架构的MPPE模型。在一项研究中,美国新墨西哥大学团队提出了一个基于Transformer的模型家族,以实现实时多人二维姿态估计。
研究人员通过改进解码器架构并采用关键点相似度度量,能够同时生成正向与反向查询,从而提升架构内查询选择的质量。与现有最优模型相比,所提出模型的训练效率大幅提升——训练周期缩短5至10倍,在保持相当推理速度的同时无需借助量化库加速。另外,模型在参数量显著减少的情况下仍能取得具有竞争力的结果,甚至表现更优。
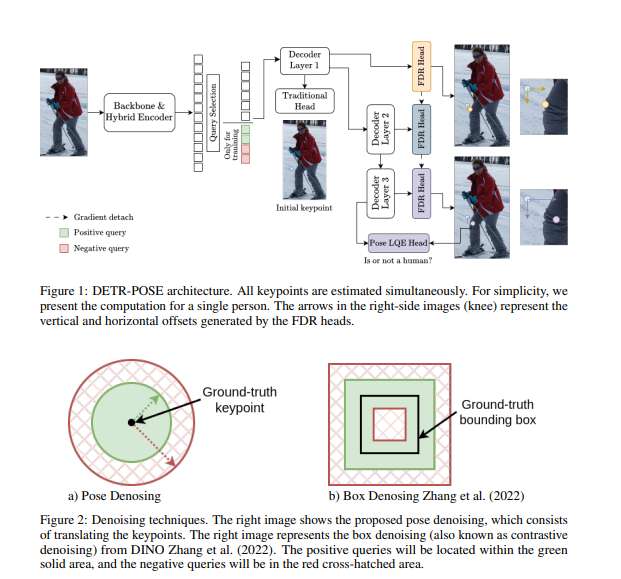
多人姿态估计(MPPE)旨在从图像中所有人体实例中检测关键点。作为虚拟现实等大型系统的核心组件,MPPE是计算机视觉领域的基础性问题,其快速计算能力对所有实时应用至关重要。尽管姿态估计模型的精度已显著提升,但现有模型依然存在高延迟问题,制约了实时应用发展。
......(全文 1737 字,剩余 1341 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限










