韩国研究团队提出无训练高帧率视频生成方法DiffuseSlide

它不仅计算高效,而且能适应多种视频生成任务,非常适用于虚拟现实等领域
(映维网Nweon 2025年09月22日)扩散模型的最新进展彻底改变了视频生成技术,能够创建高质量、时间一致性强的视频序列。然而,由于长序列中存在的闪烁和画质退化问题(尤其是在快速运动场景中),生成高帧率视频依然是一项重大挑战。现有方法常受限于计算效率低下以及在长序列中保持视频质量的局限性。
在一项研究中,韩国RECON Labs,延世大学和成均馆大学团队提出了一种基于预训练扩散模型的无训练高帧率视频生成方法DiffuseSlide。所提出方法通过创新性地利用低帧率视频中的关键帧,结合噪点重注入和滑动窗口潜在去噪技术,无需额外微调即可实现平滑连贯的视频输出。大量实验表明,所提出方法显著提升了视频质量,增强了时间连贯性与空间保真度。它不仅计算高效,而且能适应多种视频生成任务,非常适用于虚拟现实等领域。
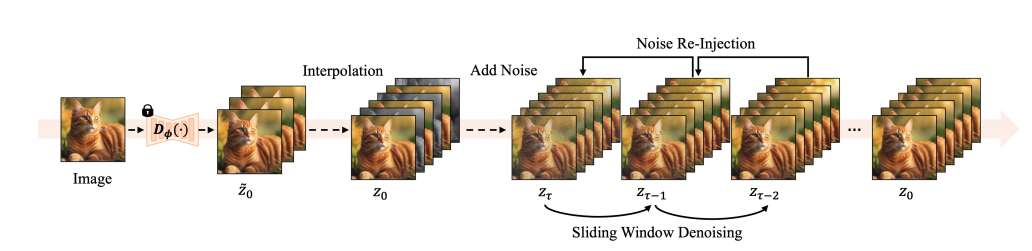
近期技术进步显著提升了视频生成能力,通过大规模数据集、先进神经网络架构和复杂训练技术的结合,当前最先进的扩散视频模型能够生成兼具空间和时间保真度的逼真且内容丰富的视频序列。这一突破性进展使其成为沉浸式AR/VR环境等应用的重要工具。
......(全文 2988 字,剩余 2535 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限







