杭州电子科技大学开发无监督3D人脸重建算法

从单视图图像中精确地重建三维形状
(映维网Nweon 2025年08月08日)在一项研究中,杭州电子科技大学团队提出了一种无监督学习方法,在不依赖外部监督信号或先验形状模型的情况下,从单视图图像精确地重建三维形状。所述创新方法通过在现有数据执行姿势转换来生成不同角度的新图像和深度图,特别关注极端姿势下的图像重建。通过使用新生成的图像和深度图作为训练样本,研究人员重新输入模型并使用生成的预测深度图对其进行优化。
实验结果表明,所提出方法在单视图人脸3D重建任务中具有优异的性能,特别是在极端姿态下,明显优于传统方法。
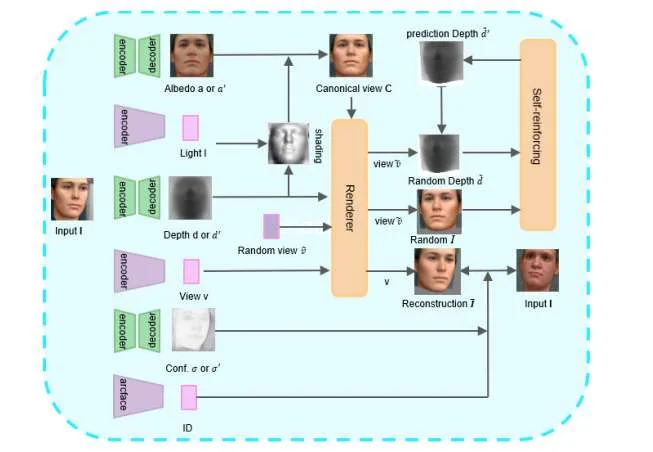
随着计算机视觉领域的不断发展,3D重建技术在虚拟现实和增强现实等领域得到了广泛的应用。然而,尽管相关应用对高质量的三维重建有很大的需求,但如何从单视图图像中准确地恢复三维形状,特别是在复杂的位姿变化下,依然是一个迫切的挑战。
......(全文 2019 字,剩余 1674 字)








