慕尼黑工业大学研发LLM驱动的VR自然语言导航系统

免手操作的移动机制
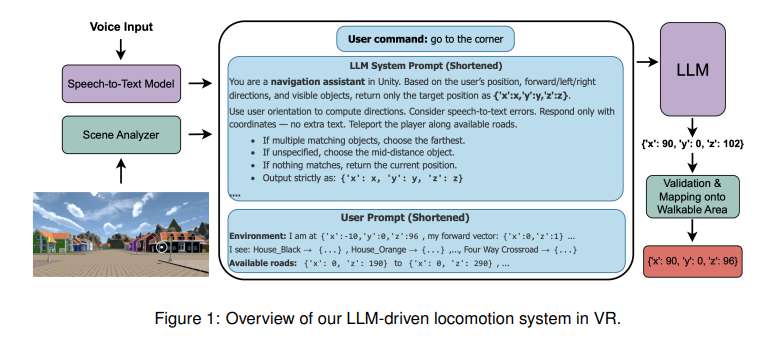
(映维网Nweon 2025年08月04日)在虚拟现实环境中,移动机制在塑造用户体验方面起着至关重要的作用。特别是,免手操作的移动机制提供了一个有价值的选择,通过支持无障碍性和解放用户对手持控制器的依赖。传统的语音方法往往依赖于严格的命令集,限制了交互的自然性和灵活性。在一项研究中,慕尼黑工业大学提出了一种由大型语言模型LLM驱动的新型移动机制,以允许用户使用具有上下文感知的自然语言来导航虚拟环境。
团队评估了三种方法:基于控制器的传送,基于语音的转向和语言模型驱动的方法。评估措施包括眼动追踪数据分析,包括通过SHAP分析进行可解释的机器学习,以及关于可用性、临场感、晕动症和认知负荷的标准化问卷,以检查用户的注意力和参与度。
研究结果表明,LLM驱动的移动机制具有与传送可媲美的可用性,临场感和晕动症得分,展示了其作为一种舒适的,以自然语言为基础的,免手操作方案的新潜力。另外,它增强了用户在虚拟环境中的注意力,而这意味着更大的参与度。
......(全文 4080 字,剩余 3687 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限