OPPO与华盛顿大学研发PanoDreamer 3D场景生成框架

3D场景生成框架
(映维网Nweon 2025年07月18日)根据文本描述、参考图像或两者自动生成完整3D场景在虚拟现实等领域具有重要应用。然而,目前的方法经常产生低质量的纹理和不一致的3D结构。为了解决所述挑战,OPPO和圣路易斯华盛顿大学团队提出了PanoDreamer,一个具有灵活文本和图像控制的一致3D场景生成框架。
所述方法采用大型语言模型和warp-refine管道,首先生成一组初始图像,然后将它们合成成360度全景图。这个全景然后提升到3D,形成一个初始点云。接下来,使用数种方法从不同的角度生成与初始点云一致的附加图像,并扩展/细化初始点云。给定结果图像集,研究人员利用3D高斯飞溅来创建最终的3D场景,然后可以从不同的角度渲染。实验证明了PanoDreamer在生成高质量、几何一致的3D场景方面的有效性。
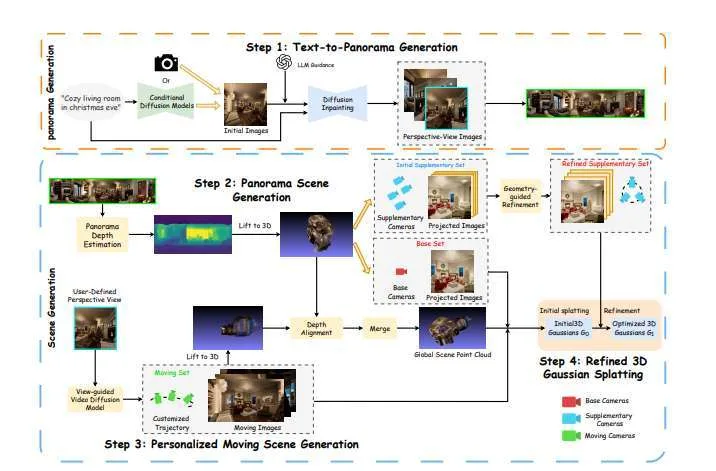
在VR/AR等行业中,文生3D的巨大潜力有望建立一种强大的沉浸式场景内容创作方法。扩散模型的最新发展使得从文本生成高质量、几何正确的图像成为可能,从而允许定制2D内容生成。基于2D文本到图像生成的最新进展,一系列的研究开始关注3D场景生成。有人首先基于参考图像生成初始点云,采用渐进式warp-and-refine方法完成3D场景重建。然而,由于摄像头的视场有限,相关方法需要多次迭代才能生成完整的场景,而且每次迭代都完全依赖于前一阶段的信息。所以,单目深度估计的误差积累和扩散产生的伪影阻碍了模型保持长期几何和外观一致性的能力。
......(全文 2038 字,剩余 1525 字)








