澳大利亚国立大学提出单图像3D场景重建新方法FlashDreamer

一种从单个图像重建完整3D场景的新方法
(映维网Nweon 2025年06月19日)3D场景重建对于虚拟现实等应用至关重要。传统的3DGS技术依赖于从多个视点捕获的图像来实现最佳性能,但这种依赖性限制了它们在只有单个图像可用的情况下的使用。在这项研究中,澳大利亚国立大学团队介绍了FlashDreamer,一种从单个图像重建完整3D场景的新方法,并大大减少了对多视图输入的需求。
所以出方法利用预训练的视觉语言模型为场景生成描述性提示,指导扩散模型从不同角度生成图像,然后将其融合形成有凝聚力的3D重建。大量的实验表明,所提出方法有效且稳健地将单图像输入扩展到全面的3D场景中,无需进一步训练即可扩展单目3D重建能力。
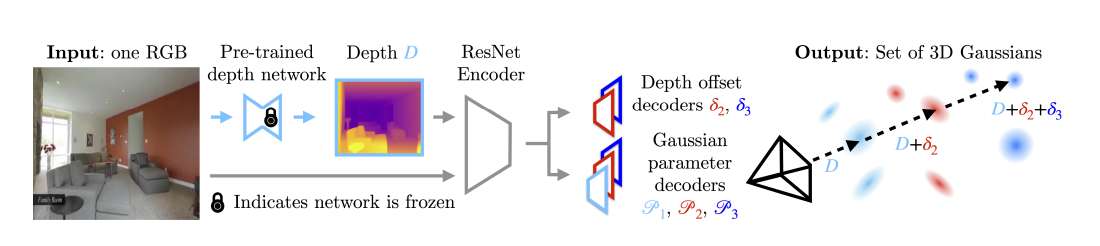
3D场景重建从多个输入图像生成场景的三维表示。这一计算机视觉中的基本任务为虚拟现实/增强现实等应用提供了空间表示。最近,3DGS作为一种3D表示方法得到了普及,它可以以最小的输入提供高质量的实时结果。然而,3DGS通常依赖于来自不同视点的多幅图像来获得最佳性能,这限制了其对单幅图像场景的适应性。
......(全文 2151 字,剩余 1758 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限







