腾讯提出Dragen3D框架实现可交互编辑的单图像3D生成

利用3DGS实现几何一致性和可控3D生成
(映维网Nweon 2025年06月18日)单图像三维生成已经成为一个突出的研究课题,在虚拟现实等领域中发挥着至关重要的作用。然而,现有方法在生成过程中缺乏多视图几何一致性和可控性等问题,严重制约了其可用性。为了应对所述挑战,腾讯团队提出了Dragen3D。
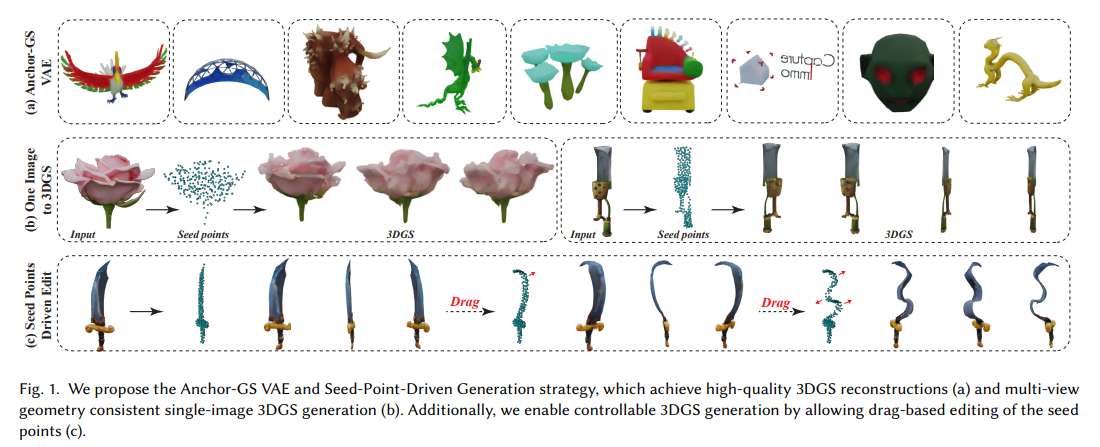
这是一种利用3DGS实现几何一致性和可控3D生成的新方法。团队引入了锚定-高斯变分自编码器,以将点云和单幅图像编码为锚定latent,并将latent解码为3DGS,从而实现了高效的latent-space生成。
为了实现多视图几何的一致性和可控生成,研究人员提出了一种种子点驱动策略:首先生成稀疏的种子点作为粗略的几何表示,然后通过种子锚点映射模块将其映射到锚点。通过易于学习的稀疏种子点来保证几何一致性,用户可以直观地拖动种子点来变形最终的3DGS几何,并通过锚点传播变化。它实现了几何可控的3D高斯生成和编辑,不依赖于2D扩散先验,并提供与最先进方法相当的3D生成质量。
......(全文 1952 字,剩余 1594 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限










