中佛罗里达大学团队提出3D视觉语言高斯飞溅新框架

在视觉和语言模态之间取得平衡
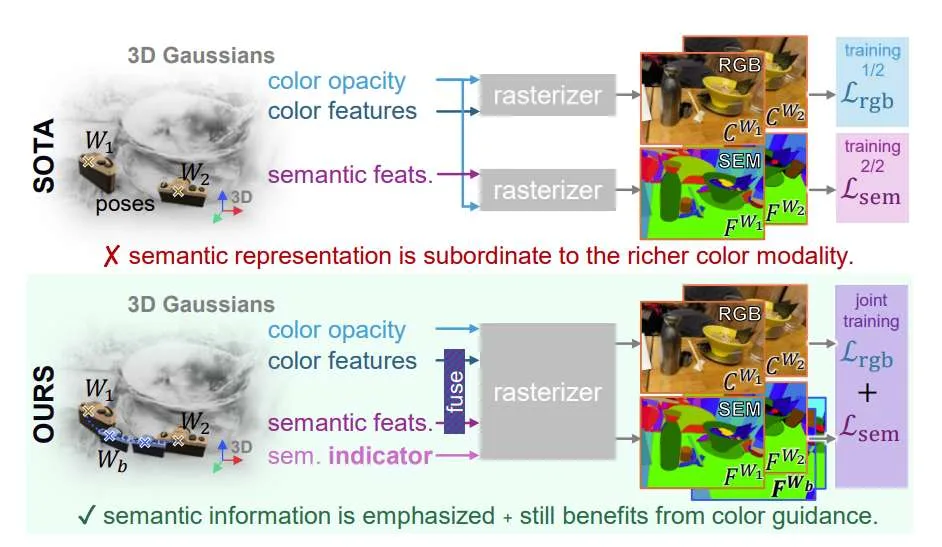
(映维网Nweon 2025年03月13日)3D重建方法和视觉语言模型的进步推动了多模态3D场景理解的发展,而这在虚拟现实/增强现实等领域具有重要应用。然而,目前的多模态场景理解方法将语义表示直接嵌入到三维重建方法中,没有在视觉和语言模态之间取得平衡,导致半透明或反射物体的语义光栅化效果不理想,以及颜色模态的过度拟合。
为了缓解所述限制,中佛罗里达大学和United Imaging Intelligence团队提出了一个充分处理不同视觉和语义模式的解决方案,即用于场景理解的3D视觉语言高斯飞溅模型,以强调语言模态的表示学习。
团队提出了一种新的跨模态光栅化器,使用模态融合和平滑的语义指示器来增强语义光栅化。他们同时采用了摄像头视图混合技术来提高现有视图和合成视图之间的语义一致性,从而有效地减轻了过度拟合。大量的实验表明,所提出方法在开放词汇语义分割中达到了最先进的性能,大大超过了现有的方法。
......(全文 1456 字,剩余 1093 字)











