Meta开源AI模型ImageBind,助力创造身临其境多感官体验

帮助我们轻松创造身临其境的多感官体验
(映维网Nweon 2023年05月10日)Meta日前开源了一种可以将可以横跨6种不同模态的全新AI模型ImageBind,包括文本、音频、视觉数据、温度和运动读数。目前,相关源代码已托管至GitHub。
对于以往的AI系统,每个模态都拥有特定的嵌入,一般只支持一个或两个模态,而不同模态之间难以进行互动和检索。例如,你无法直接根据音频来准确检索出相关图像和视频。但ImageBind可以将六种模态的嵌入对齐到一个公共空间,从而实现跨模态检索。
换句话说,你只需提供一种形式的输入,它就能够将其与其他模态联系起来。举个例子,如果提供一张海浪的图片,ImageBind就可以检索海浪的声音;如果你提供老虎的图片和瀑布的声音,系统就可以自动生成一个老虎行走在瀑布前的视频。
当然,所述模型目前只是一个研究项目,暂时没有直接的消费者应用。然而,这种生成式AI显然可以帮助我们轻松创造身临其境的多感官体验。例如,当你要求VR设备提供在天空中翱翔的场景时,系统可以马上匹配相应的画面,声音和触感。

这项研究的核心概念是将多种类型的数据链接到一个多维索引中,亦即嵌入空间。诸如DALL-E、Stable Diffusion和Midjourney等人工智能图像生成器都依赖于在训练阶段将文本和图像链接在一起的系统。
它们在视觉数据中寻找模态,同时将相关信息与图像描述联系起来。这使得系统能够根据用户的文本输入生成图片。
对于ImageBind,Meta表示它是第一个将六种类型的数据组合到单个嵌入空间中的模型。模型包含的六种类型的数据是:视觉数据(以图像和视频的形式);温度(红外图像);文本音频深度信息;以及由惯性测量单元IMU产生的运动读数。
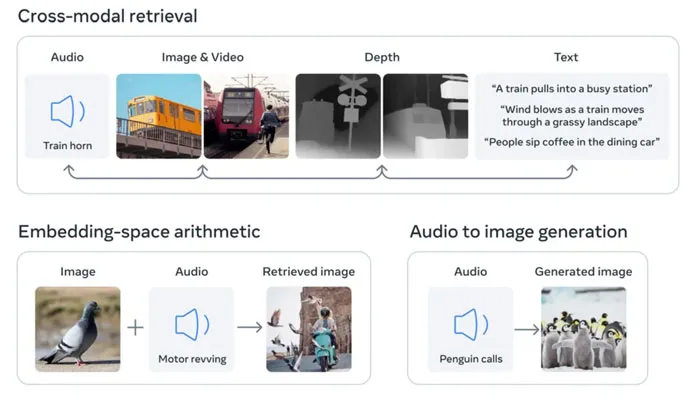
随着这种多模态AI模型的发展,未来的人工智能系统将能够像当前的文本输入一样,交叉引用各种不同的数据。我们不难想象,对于正在积极探索元宇宙的Meta而言,VR设备不仅可以生成音频和视觉输入,同时可以生成相关的环境和动作。
例如,穿戴VR头显的你可以要求体验一次海上航行,而系统不仅会提供站在巨轮甲板的场景,同时包括海浪的噪音和特有的凉爽海风。
Meta指出,未来的模型可以添加其他感官输入流,包括“触摸、语音、嗅觉和大脑功能磁共振信号”。它同时声称,这项研究“令机器离人类同时地、全面地、直接地从多种不同形式的信息中学习的能力又近了一步”。
实际上,现在AI正在为创作者提供了巨大的帮助,而随着相关技术的提升,沉浸式内容创作将会越发轻松简单,并带来数量和质量方面的极大提升。
......(全文 903 字,剩余 0 字)








